A communication channel is defined as any physical medium whereby we may transmit or receive information. It may be wire, cable, radio waves or a beam of light. The destination and/or source may be a person or a memory device like a tape or a computer disk. As a matter of physics, the capacity of a channel is defined by Hartley’s law as C = B x T . Ralph Hartley was a precursor to Shannon and his law from 1927 states that in order to transmit a specific message, a certain fixed product is required. The product (the channel capacity C) is defined by the bandwidth B multiplied by the time T. For the same message to be transmitted in half the time thus requires a double bandwidth.
Two main kinds of channels can be discerned: the discrete or digital channel applicable to discrete messages such as English text, and the continuous or analogue channel, long used to convey speech and music (telephone and LP records).
To apply information theory on continuous channels is possible by use of the sampling theorem. This theorem states that a continuous signal can be completely represented and reconstructed by sampling and quantifying made at regularly intervals. Sufficiently microscopic fragmentation of the waveform into a number of discrete equal parts bring about a smooth change from the continuous to the more easily calculated discrete channel. See Figure 4.10.
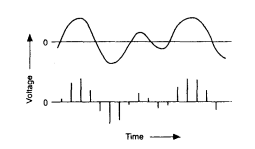
Figure 4.10 Measurement of amplitude samples in a continuous signal.
A message arriving at its destination may differ both structurally and functionally from the original because of noise. Thus, information is always lost to some extent, which means that the amount of information can never increase during the course of the transference of a certain message, only decrease. The existing noise in the channel is a kind of negative information. It is preempting the selective power of the channel leaving a residue for the desired signal.
Structural differences between a message sent and the message re- ceived are defined as syntactic noise. Examples are when a telephone call is distorted or when raindrops dissolve the ink script of a letter. Misinterpretation by ambiguity in the denotation of a message is called semantic noise. Bad spelling or choice of inappropriate phrases are typical examples. Pragmatic noise is not produced by the sender but is everything that appears in connection with the message and decreases its readability. A bad radio receiver may produce pragmatic noise.
However syntactically noisy a message is, it may not create pragmatic noise and can therefore at least theoretically be received correctly. A syntactically noiseless message may, on the other hand, fail its intention through environmental noise disturbing the receiver. Syntactic and semantic noise may generate pragmatic noise but need not necessarily do so.
Messages transmitted in electronic channels are always, to a greater or lesser extent, affected by certain harmful electrical influences or transmission noise. Of these types of noise, white noise is the most common. It is assumed to be random and non-Gaussian, making the message and the noise statistically independent. As its elements are independent of the communication channel it can be relatively easily filtered out by various technical means. System-dependent, or black noise, has certain dependencies between its elements. It is nonGaussian, often highly non-linear, and cannot be dealt with as separated from the system and the message. Up to now, the complex nature of black noise has prevented the development of reliable methods for its calculation and neutralization.
One method of solving problems caused by noise is to ensure a suitable amount of redundancy in the language used. General redun- dancy can also be achieved by different means such as repetition of the message, change of channel and form and the use of feedback in the communication process. Another method is efficient coding, which will decrease the negative effects of noise.
The acquisition of information is a flow from noise to order — a process converting entropy to redundancy. During this process, the amount of information decreases but is compensated by constant re- coding. In the recoding the amount of information per unit increases by means of a new symbol which represents the total amount of the old. The maturing thus implies information condensation. Simultaneously, the redundance decreases, which render the information more difficult to interpret. Compare with the use of stenography which considerable reduces the letter content in the translation from speech to text.
Information must always be transmitted in some physical form, which seldom has the same shape in which it is actually created. Transmissions therefore has to be coded because it is only in a coded form that the channel will permit the message to propagate. (A message conveyed without coding would be the equivalent of telepathy.) The code determines how a succession of symbols (numerals, letters, signs, etc.) can be replaced by another, not necessary equal long succession.
Choice of an appropriate code for the channel will actually improve the operating efficiency of the communication system. Optimum utilization of the channel capacity is therefore a problem of matching a code to the channel in such a way as to maximize the transmission rate. A further, different reason for the use of codes is secrecy.
A code determines how a succession of symbols (numerals, letters, signs, etc.) can be replaced by another, not necessarily equal, long succession. The symbols used by the code may not be of the same kind as the original symbols used and all information, even the most complex, can be coded. Well-known codes are the Morse code used in telegraphy, the Baudot code used in teletype and the ASCII code used in the binary representation of computer languages. The transformation of a message by use of a code, coding, can however only be carried out for a meaningful message. Transformation of characters in a message apart from the meaning can only be effected by use of cryptography. The transformation of a message in order to regain its original content is called decoding.
To study how a message can be most efficiently encoded (normally in an electronic channel) is one of the chief aims of information theory. Its subarea of coding is however both vast and complicated and only some of its main principles may be outlined here. Let us however begin with coding of decimal numerals. Calculations earlier in this chapter showed that combinations of three binary digits were inadequate to express the existing numerals. Four binary combinations give 16 possibilities, a surplus of 6 (see below).

Five binary combinations give 32 possibilities, enough for the basic letters of the alphabet, but not for all the characters of a normal keyboard which requires about 50 keys. Here, the use of 6 binary digits gives 64 possibilities, a surplus of 14 for a keyboard with no upper case. To express all the characters of a normal keyboard including upper case thus requires at least 7 binary digits, which gives 128 combinations.
If we want to express a three-digit number, there are two different possibilities. One way is to let the information source select three times in the basic repertoire of ten digits which gives 3 x 3.32 = 9.96, i.e. 10 bits. The other way is a choice in the repertoire of existing three-digit numbers between 100 and 999 which gives log2900 = 9.4, i.e. 9 bits. Obviously, the second method is a little more efficient than the first which in turn is more comfortable for human mental capacity. Our decimal system is derived from calculations with hands, feet and a limited short-term memory.
It is now possible to understand that block coding will reduce the number of digits used in the binary code when coding both numerals and letters. In a message, any sequence of decimal digits may occur, while letters in English words occur according to certain rules. To encode whole words by a sequence of binary digits is therefore more efficient compared to coding the letters individually. Here, inherent statistical laws of the English language give an average of 4.5 letters per word requiring 14 binary digits or 2.5 binary digits per character.
Source: Skyttner Lars (2006), General Systems Theory: Problems, Perspectives, Practice, Wspc, 2nd Edition.